DeepSeek's Open Source Week: Five Powerful Tools

DeepSeek's Open Source Week brought a breath of fresh air to the AI community, unveiling a series of innovative tools and updates that promise to reshape how we approach artificial intelligence. This event, detailed in various tech reports and GitHub repositories, aimed to provide the global AI community with tools that enhance model training and inference efficiency. Here’s a closer look at the highlights.
Detailed Examination of Each Repository
1. FlashMLA: Efficient MLA Decoding Kernel for Hopper GPUs
- Description: FlashMLA is designed to optimize decoding processes on Hopper GPUs, specifically for variable-length sequences. It is a critical component for AI models requiring high-speed inference, such as language models.
- Technical Details: Supports BF16 and FP16, with paged KV cache (block size 64), achieving performance metrics of 3000 GB/s memory-bound and 580 TFLOPS compute-bound on H800 SXM5, using CUDA 12.8. It requires Hopper GPUs, CUDA 12.3+, and PyTorch 2.0+.
- Community Impact: This tool is particularly useful for developers working on natural language processing, offering a battle-tested solution for production environments.
- Unexpected Detail: Its performance metrics, such as 580 TFLOPS compute-bound, highlight its suitability for high-performance computing, which might not be immediately obvious to those focused on software rather than hardware.
2. DeepEP: EP Communication Library for MoE and Expert Parallelism
- Description: DeepEP facilitates efficient communication in Mixture-of-Experts (MoE) models, essential for distributed AI systems. It provides all-to-all GPU kernels for dispatch and combine operations.
- Technical Details: Supports FP8 low-precision operations, includes kernels for asymmetric-domain bandwidth forwarding (NVLink to RDMA), and offers low-latency kernels for inference with pure RDMA. It requires Hopper GPUs, Python 3.8+, CUDA 12.3+, PyTorch 2.1+, NVLink, and RDMA network, with dependencies on modified NVSHMEM.
- Performance Metrics: Intranode operations achieve 153-158 GB/s, while internode operations range from 43-47 GB/s, depending on the number of experts, as shown in the table below for H800 with NVLink and RDMA configurations.
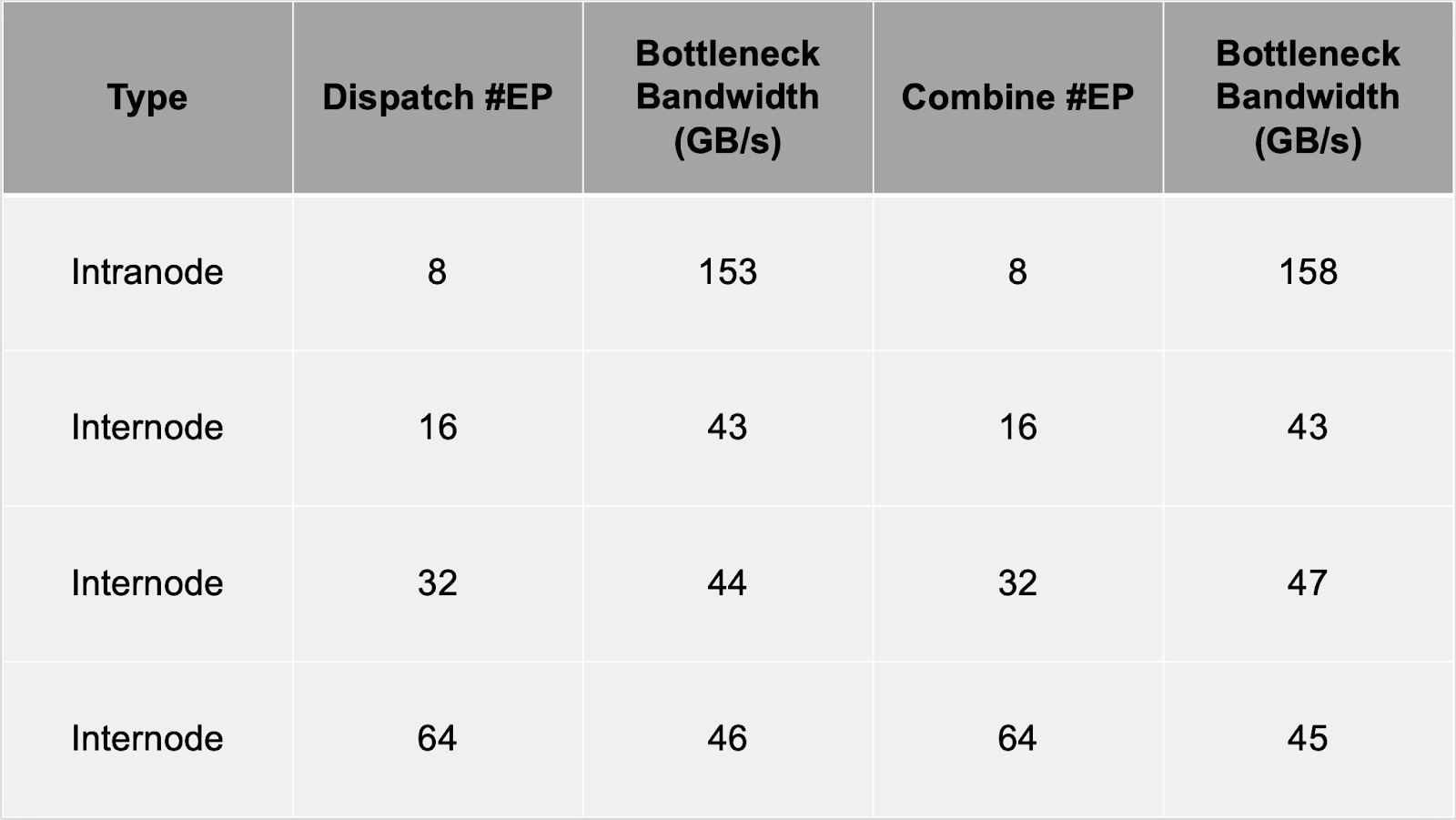
- Community Impact: Enhances scalability for large-scale MoE models, with compatibility for InfiniBand and theoretical RoCE support.
3. DeepGEMM: FP8 GEMM Library for Efficient Matrix Multiplications
- Description: DeepGEMM focuses on General Matrix Multiplications (GEMMs) using FP8 precision, optimized for Hopper architecture, supporting both dense and MoE grouped GEMMs.
- Technical Details: Written in CUDA with JIT compilation, no heavy dependencies, core kernel ~300 lines, achieves up to 1358 TFLOPS on Hopper GPUs. It requires sm_90a GPUs, Python 3.8+, CUDA 12.3+, PyTorch 2.1+, and CUTLASS 3.6+.
- Performance Metrics: Outperforms CUTLASS 3.6 in various configurations, with speedups ranging from 1.1x to 2.7x, as detailed in the table below for H800 SXM5.
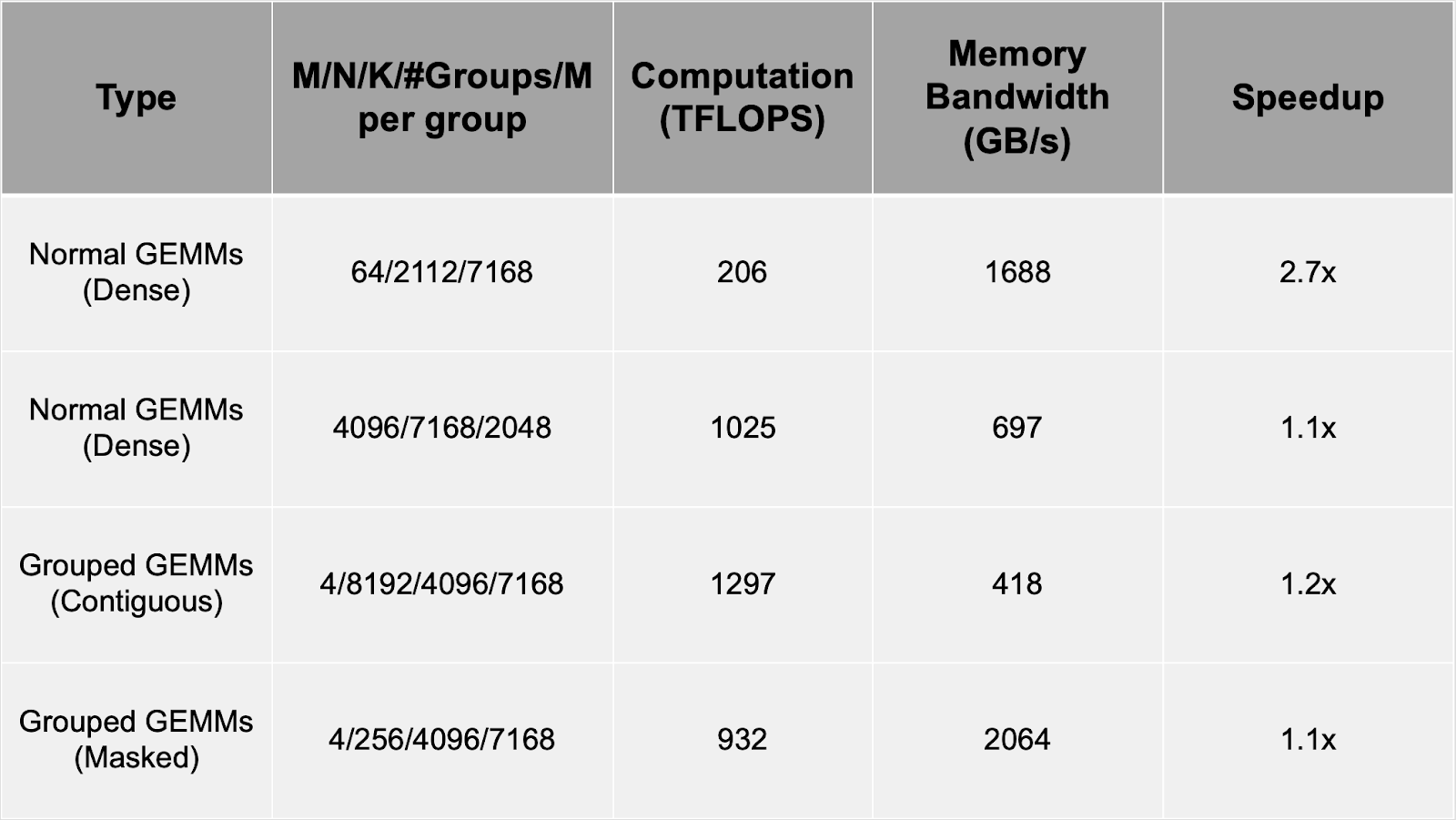
- Community Impact: Offers a lightweight, high-performance alternative for matrix operations, crucial for neural network computations.
4. DualPipe: Bidirectional Pipeline Parallelism Algorithm
- Description: DualPipe is an algorithm for overlapping computation and communication in AI model training, reducing pipeline bubbles and enhancing efficiency.
- Technical Details: Detailed in the DeepSeek-V3 Technical Report (DeepSeek-V3), it achieves full overlap of forward and backward phases, requiring PyTorch 2.0+ and custom overlapped_forward_backward methods for real-world applications.
- Community Impact: Improves training speed for large models, particularly DeepSeek-V3 and R1, by minimizing idle time.
5. 3FS: High-Performance Parallel File System
- Description: 3FS, or Fire-Flyer File System, is designed for AI workloads, providing a shared storage layer with high throughput and strong consistency.
- Technical Details: Disaggregated architecture, achieves 6.6 TiB/s aggregate read throughput on a 180-node cluster, supports data preparation, dataloaders, checkpointing, and KVCache for inference, with peak read throughput up to 40 GiB/s for KVCache lookups.
- Performance Metrics: GraySort benchmark sorted 110.5 TiB in 30 minutes 14 seconds, achieving 3.66 TiB/min on a 25-node cluster, as shown in documentation images.
- Community Impact: Simplifies data management for AI training, offering a robust solution for large-scale data access.
Powering the Future of AI with Bitdeer AI
As DeepSeek continues to drive innovation through its open-source contributions, the need for robust infrastructure becomes ever more critical. Bitdeer AI offers a powerful GPU cloud platform that provides scalable, serverless solutions tailored for high-performance AI workloads. With options ranging from bare metal to containerized deployments, Bitdeer AI enables developers to push the boundaries of their projects without worrying about hardware limitations. Their AI Studio streamlines the entire machine learning lifecycle, supporting frameworks like TensorFlow and PyTorch, and ensuring that infrastructure is as advanced as the models it powers.
DeepSeek’s week of groundbreaking updates, complemented by Bitdeer AI’s cutting-edge services, sets the stage for a new era in AI development. Together, these innovations not only simplify complex workflows but also pave the way for the next wave of transformative breakthroughs in artificial intelligence.