Mixture of Experts (MoE) Models: Why They’re Gaining Traction in Efficient AI Model Training

As AI models continue to scale in complexity and capability, one of the biggest challenges researchers and enterprises face is balancing performance with efficiency. The Mixture of Experts (MoE) architecture has emerged as a game-changing solution, enabling large AI models to achieve higher performance while reducing computational costs. In this article, we explore what MoE models are, why they are gaining traction, and how they can revolutionize AI model training.
What is a Mixture of Experts (MoE) Model?
MoE is a type of neural network architecture designed to dynamically allocate computing resources based on input data. Unlike traditional dense models, where all parameters are utilized for every inference, MoE uses a gating mechanism to activate only a subset of specialized “expert” networks per task. This selective activation allows for efficient computation, reducing the number of parameters actively used while maintaining model performance.
Key Components of MoE:
- Experts: Individual neural networks trained to specialize in different parts of the input space.
- Gating Network: A mechanism that learns to route input data to the most relevant experts.
- Sparse Activation: Only a few experts (e.g., 2 out of 16) are activated per forward pass, leading to lower compute costs.
Why MoE is Gaining Traction
1. Scaling Without Proportional Compute Costs
Traditional deep learning models require more computational resources as they grow in size. However, MoE models allow for massive parameter scaling while keeping computational costs low.
2. Improved Efficiency for AI Training
Since only a fraction of the model’s experts are used at a time, MoE enables:
- Faster training times due to fewer activated parameters.
- Lower memory and energy consumption compared to dense models.
- Better generalization by distributing learning across specialized experts.
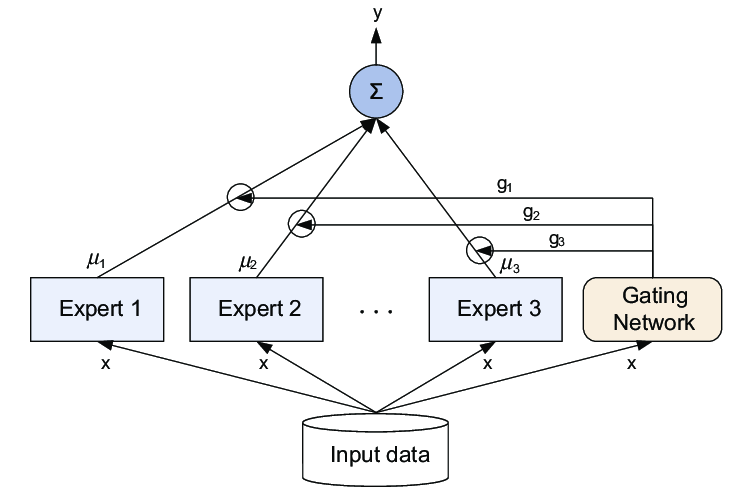
Fig 1: The architecture of the mixture-of-experts model*
3. Better Adaptability for Complex Tasks
MoE models shine in scenarios that require handling diverse and multimodal data. For instance:
- Natural language processing (NLP): MoE models improve efficiency in large-scale NLP tasks.
- Computer vision: MoE enhances model adaptability for multi-task learning.
- Multimodal AI: Experts can specialize in text, image, and audio data, improving performance across domains.
Leading Large Language Models (LLMs) Using MoE
Several cutting-edge LLMs have adopted the MoE approach to enhance efficiency and scalability. The top three include:
- DeepSeek-V3: A massive 685-billion-parameter model with 256 experts, activating 8 routed experts per token. This architecture significantly improves efficiency and reduces training costs compared to dense models.
- Jamba 1.5 Large: A state-of-the-art MoE model optimized for low latency and high efficiency, leveraging a hybrid MoE structure to improve inference speed while maintaining accuracy.
- Qwen 2.5 Max: An advanced multimodal MoE model designed for both language and vision tasks, showcasing strong adaptability across different AI applications.
Business Use Cases for MoE Models
1. Video Gaming & AI-Driven NPC Behavior
The gaming industry leverages MoE models to enhance AI-driven non-player character (NPC) behavior. By dynamically selecting experts for different in-game scenarios, MoE models enable NPCs to react more intelligently and adapt to player actions in real-time, leading to more immersive experiences.
2. Financial Services & Fraud Detection
Banks and fintech companies use MoE architectures for fraud detection and risk assessment. By routing transactions through specialized experts trained on different fraud patterns, MoE models can provide more accurate fraud predictions with lower latency.
3. Video Model Training & AI-Powered Content Creation
MoE models are transforming video model training by optimizing content creation workflows. AI-generated videos benefit from MoE architectures as they enable specialized experts for scene recognition, motion synthesis, and object tracking, making the automation of video production more efficient.
4. Autonomous Vehicles & Smart Traffic Systems
Self-driving cars rely on MoE models to process vast amounts of sensor data efficiently. Experts can specialize in tasks like pedestrian detection, road sign recognition, and vehicle tracking, making real-time decision-making more efficient.
5. Enterprise AI & Workflow Automation
Enterprises adopting AI-powered workflow automation benefit from MoE models as they allow adaptive task allocation. AI assistants powered by MoE can dynamically route requests to the best-suited experts, enhancing operational efficiency and decision-making.
Challenges and Considerations
While MoE presents significant advantages, there are challenges to address:
- Training Complexity: MoE models require careful tuning of the gating mechanism to avoid under-utilization or over-specialization.
- Communication Overhead: Distributing computation across multiple experts can introduce latency in distributed training.
- Inference Costs: While training is optimized, deploying MoE models may require specialized hardware setups for efficient inference.
The Future of MoE and AI Training
As AI continues to evolve, MoE architectures are expected to play a key role in making model training more efficient and scalable. The combination of serverless GPU cloud computing, AI workflow automation, and MoE models could unlock unprecedented performance gains for AI applications—from NLP to computer vision and beyond.
At Bitdeer AI, we recognize the potential of MoE models in optimizing AI training workloads. By leveraging our multi-node GPU cloud infrastructure, businesses can efficiently train and deploy next-generation AI models while optimizing resource utilization.
Conclusion The Mixture of Experts (MoE) architecture is redefining AI model efficiency by enabling scalable training without proportional increases in computational costs. With the rapid adoption of MoE models across research labs and enterprises, AI developers now have a powerful tool to train smarter, not harder.
For those looking to accelerate their AI workloads, Bitdeer AI's cloud solutions provide the computing power needed to train cutting-edge models like MoE efficiently. Stay ahead in AI innovation - explore the possibilities with Bitdeer AI!
*Source: Adaptive mixture-of-experts models for data glove interface with multiple users - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/The-architecture-of-the-mixture-of-experts-model_fig1_220216747 [accessed 25 Feb 2025]