What is a Token in AI? A Comprehensive Guide for Developers and Businesses

The growing popularity of artificial intelligence (AI) has led more people to become aware of it, with the large language model being one of the most familiar aspects. In LLMs (such as DeepSeek or ChatGPT), at the core, there is something called a "token." However, you may not have looked closely at what exactly tokens are and why they are so important. In this article, we will take you deep into the world of tokens, including: the concept of tokens, their technical definitions, tokenization in different models, pricing considerations, token limits, and the business implications AI developers should be aware of.
Understanding Tokens: The Building Blocks of AI Language
What is a Token?
A token is a discrete unit of text that AI models process to interpret and generate human-like language. Depending on the tokenization method, a token might represent a full word (e.g., "intelligence"), a subword (e.g., "intelli"), or even a single character (e.g., "i"). By breaking text into tokens, AI systems can analyze and synthesize language systematically. Tokens are not just a technical detail—they’re the bridge between raw text and machine understanding, enabling everything from chatbots to code generation.
The size of a token varies by context:
- English text: On average, 1 token equals about 0.75 words due to subword tokenization (e.g., a 100-word paragraph might use 130-150 tokens).
- Code or structured data: Tokens often represent smaller, denser units, reducing the word-to-token ratio.
- Complex scripts (e.g., Chinese, Japanese): A single character may constitute a token, reflecting linguistic differences.
This variability underscores why understanding tokens is critical for optimizing AI performance and costs.
How Tokenization Works: From Text to Tokens
Tokenization is the process of splitting text into tokens for AI processing. It’s a pivotal step that influences response accuracy, computational efficiency, and cost. Different models employ distinct tokenization strategies, each suited to specific use cases:
- Whitespace-based Tokenization: Splits text based on spaces and punctuation. Example:
- Sentence: "Artificial Intelligence is evolving rapidly."
- Tokens: ["Artificial", "Intelligence", "is", "evolving", "rapidly", "."] (6 tokens)
- Subword Tokenization (Byte-Pair Encoding, BPE): Breaks words into subwords to handle unknown words effectively.
- Example: "Artificial" → ["Artifi", "cial"]
- Used in GPT models.
- Character-based Tokenization: Each character is a token.
- Example: "AI" → ["A", "I"]
- Common for languages with complex scripts (Chinese, Japanese).
- WordPiece Tokenization: Similar to BPE, used in models like BERT, which learns subword units from a vocabulary. Developed by Google, it began with voice search in Japanese and Korean.
- SentencePiece Tokenization: A more flexible approach which is capable of handling spaces, punctuation, and rare words.
Efficient tokenization reduces the number of tokens processed, lowering costs and speeding up responses. For instance, subword methods excel at handling out-of-vocabulary words, while character-based approaches ensure universality at the expense of higher token counts.
Token Limits: Constraints and Considerations
Every AI model has a token limit—the maximum number of tokens it can process in one request, encompassing both input (prompt) and output (response). Exceeding this limit results in truncation, where older tokens are discarded, potentially losing critical context.
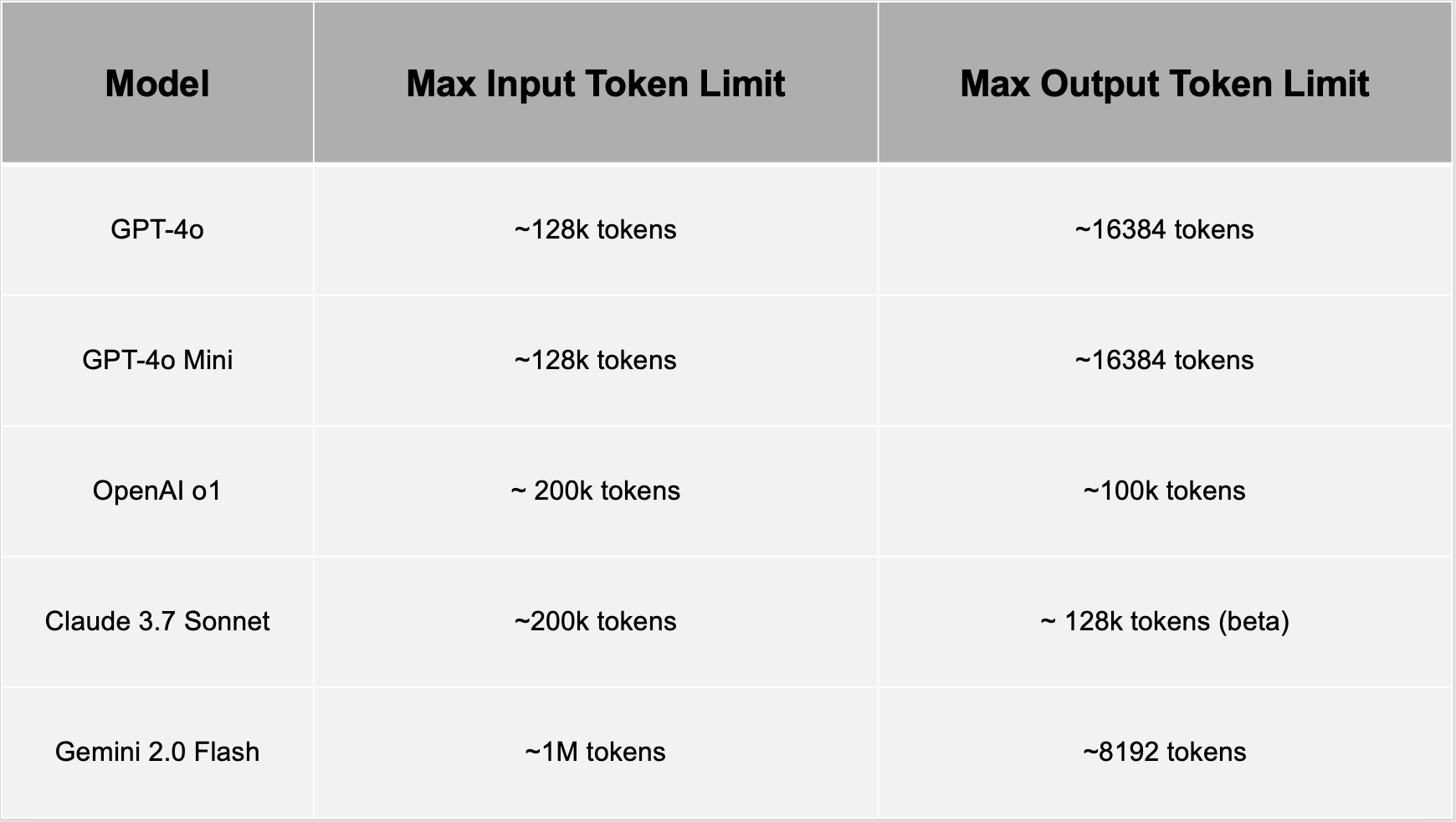
Developers must design prompts and responses to stay within these boundaries, ensuring the model retains essential information. Token limits directly affect usability in tasks like summarizing long documents or maintaining extended conversations.
Token Pricing: The Economics of AI Usage
AI services like ChatGPT and Gemini operate on a token-based pricing model. Companies charge based on the number of tokens processed in a request. Pricing is typically divided into:
- Input tokens: The number of tokens sent to the model
- Output tokens: The number of tokens generated in response
The following table shows the token pricing of the most popular LLM models now.
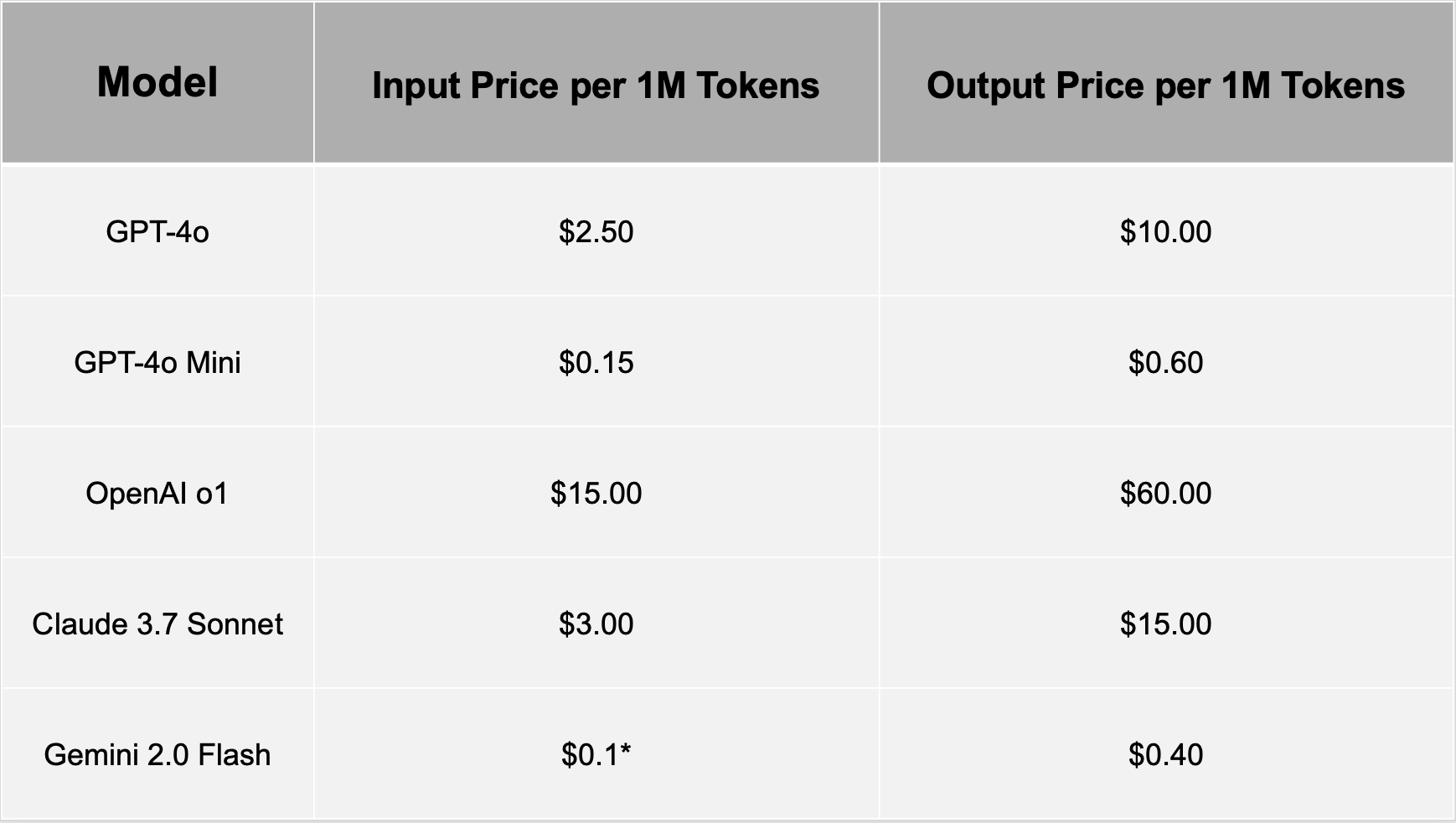
Key Factors Affect in Token Costs:
- Model Selection: Larger models like GPT-4o are more expensive than smaller models like GPT-4o Mini.
- Input Size: Longer prompts cost more. Trimming unnecessary words helps reduce costs.
- Response Length: Limiting the number of output tokens lowers expenses.
Tokenization in Model Training and Performance
Tokens aren’t just for inference; they’re central to training AI models. During training, vast datasets are tokenized to teach models linguistic patterns. The tokenization method impacts:
- Accuracy: Poor tokenization (e.g., splitting "AI" into meaningless fragments) confuses the model.
- Efficiency: Compact token representations lower computational overhead.
- Scalability: Subword methods enable models to generalize to new words.
AI developers focus on refining tokenization algorithms to improve efficiency and minimize errors.
Business Considerations for AI Developers
For developers and businesses, tokens influence more than just technical design—they shape economics and user experience:
- Cost Management: High token usage in applications like content generation can erode margins. Concise prompts and efficient models mitigate this.
- Performance: Exceeding token limits risks truncating key data, degrading output quality.
- Latency: Processing more tokens slows response times, critical for real-time applications like chatbots.
- Monetization: AI startups must align pricing (e.g., subscriptions, pay-per-use) with token consumption to ensure profitability.
Optimizing Token Usage
To maximize efficiency and minimize costs, consider these techniques:
- Prompt Engineering: Use clear, concise inputs (e.g., "Summarize this" vs. "Please provide a summary of this text").
- Summarization: Pre-process large texts to reduce token counts before model input.
- Model Selection: Match model capabilities to task needs—use smaller models for simple queries.
- Output Limits: Cap response length to control costs and latency.
Final Thoughts
Tokens are the foundation of LLM-based AI applications. Understanding tokenization, pricing, and limits helps AI developers build cost-effective, efficient, and scalable applications. Businesses leveraging AI must integrate token cost management into their pricing and usage strategies to ensure sustainable operations.
By optimizing token usage and making strategic decisions about model selection and pricing, AI developers can reduce costs while maintaining high performance and accuracy.
Note:
- *Refer to Gemini 2.0 Flash (text / image / video).
- The data above was collected in February 2025.