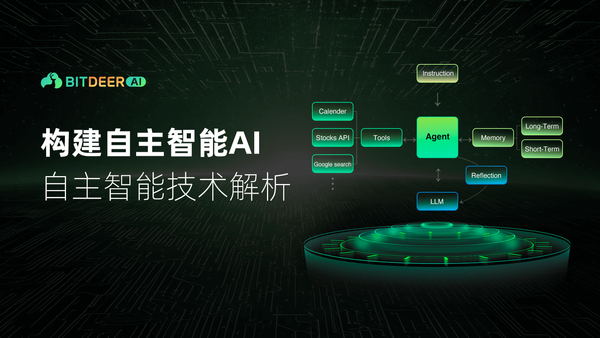
语言模型是人工智慧技术的主要应用,发展迅速。人工智慧技术可以回答各种问题,模仿人类的表达方式,并提供最新的资讯。语言模型很快就会应用于各种场合,因为它们是提高效率的必备工具。本文将介绍有关大语言模型(LLM)的内容,包括可能的用途和实现目标的方法。
什么是大语言模型?
大语言模型(Large Languge Model)的核心元件是转换器模型(Transformer model),这是一种深度学习架构。为了理解每个单字的上下文和含义,它可以根据单字之间的关系来处理句子。作为训练过程的一部分,大语言模型会收集许多成对的单词,对它们进行排序,并在它们之间建立关联。
在处理输入资料后,大语言模型会预测句子中的后续单字。它透过确定每个单字最合适的选项,不断进行预测。因此,所选单字组合成有意义且合理的内容。当试图理解某件事物时,大语言模型会利用自注意力机制来确定哪些词是最关键的。透过位置编码,模型可以获知每个词在语句中的位置,有助于理解概念流程,把握单字之间的关联。
大语言模型如何运作?
大语言模型(LLM)运作依赖一系列复杂的技术手段来处理和生成语言。这些模型的核心是自注意力机制