DeepSeek-R1 的快速部署

Bitdeer AI Cloud平台现在支持多个版本的DeepSeek模型,包括R1和JanusPro。您可以通过实例控制台一键部署实例,自定义管理模式,并灵活选择模型镜像以实现快速部署。本指南以DeepSeek-R1 671B镜像为例,提供详细的分步教程,确保最佳性能和可扩展性。
快速概览
DeepSeek-R1 是一款先进的开源 AI 推理模型,于 2025 年 1 月 20 日发布,性能可媲美 OpenAI 的 o1 模型。它专为高性能自然语言处理和生成式 AI 任务(包括数学、代码和推理)优化,并采用创新推理技术,相较传统大语言模型大幅降低计算资源需求。
- 模型详情:DeepSeek R1 671B(2.51-bit 量化)
- GPU 需求:推荐 VRAM ~300GB(4 * H100 GPU)
- 系统磁盘:>400GB
- 安全组设置:
- API 端口:40000
- SSH 密钥对:请确保已准备好 SSH 密钥对,以保障安全访问。
(更多详细信息,请参考下方操作步骤)
操作步骤
安装 DeepSeek
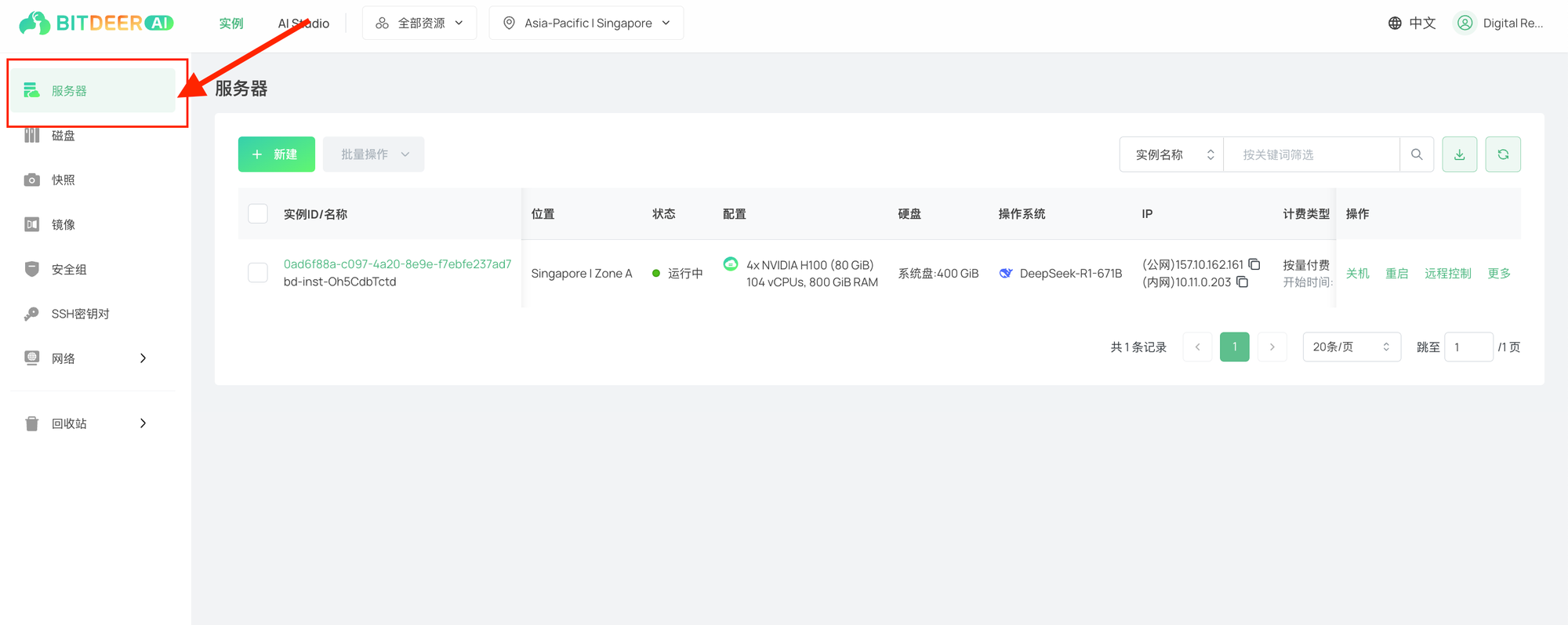
- 注册或登录实例控制台使用您的账户凭据访问云服务器控制台。
- 进入服务器管理页面在左侧导航栏中选择“服务器”,进入云服务器列表页面。然后点击“新建”创建新的实例。
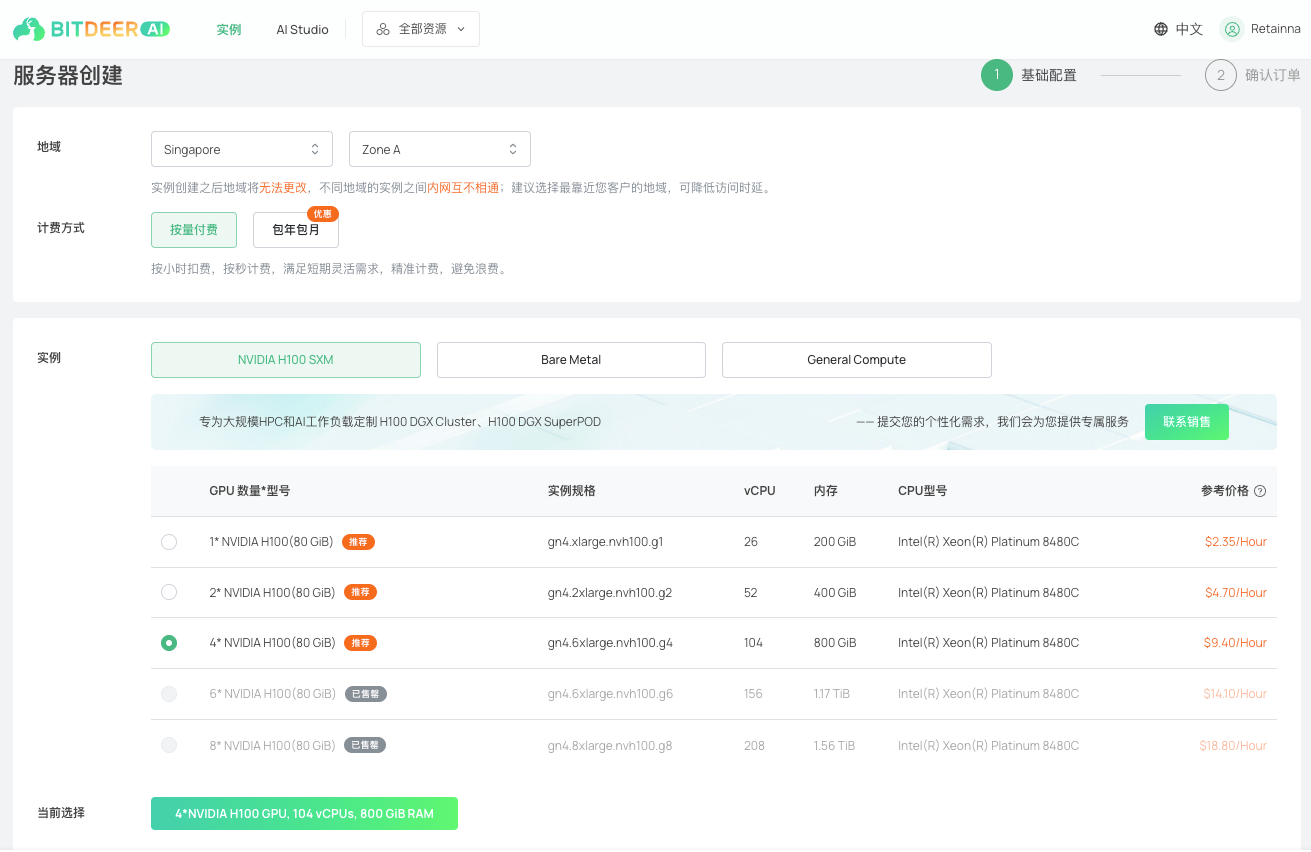
3. 配置您的云服务器(虚拟机):
- 选择您需要的区域和可用区,并设置计费方式。
- 在“实例”选择中,推荐使用 4 * NVIDIA H100 (80 GiB) 以运行 DeepSeek-R1。
c. 在“镜像”选项下,选择 AI 模型 类别,然后选择 DeepSeek-R1 671B。
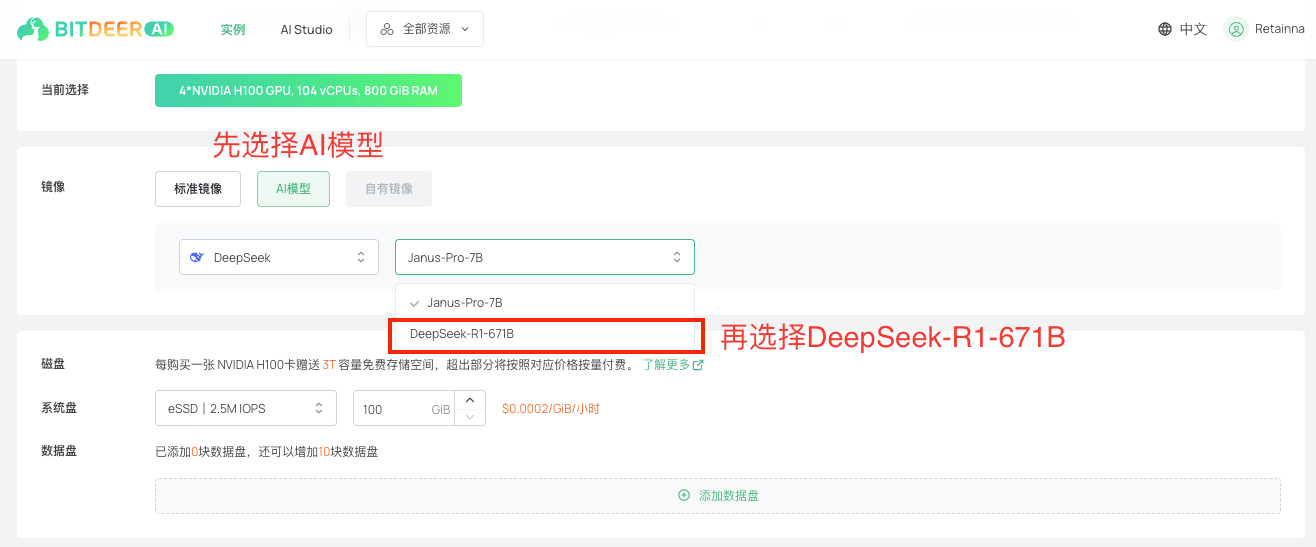
d. 在系统磁盘下,此镜像至少需要 400GB 的内存。
e. 在网络与公网 IP 地址部分,可使用默认配置。
f. 在“安全组”中,选择允许 TCP 40000 端口 入站访问的安全组,以便 API 访问。有关安全组设置的更多信息,请参阅相关指南。
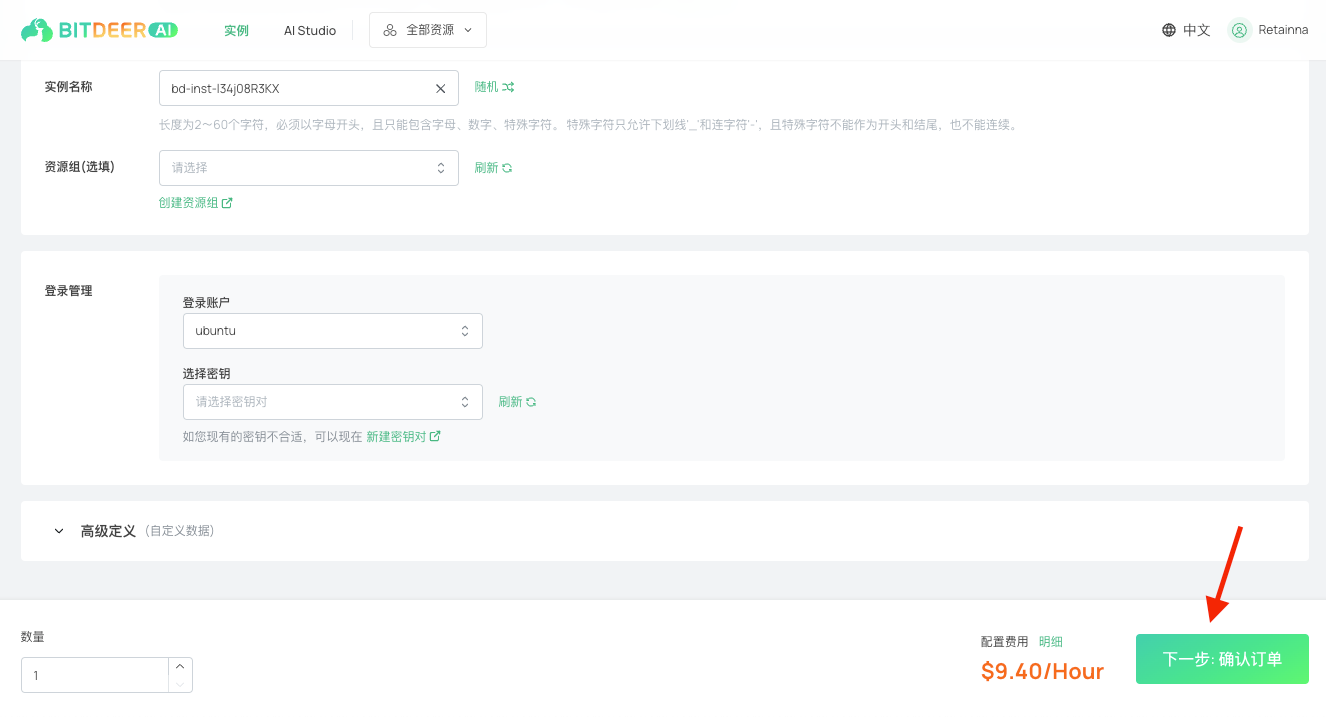
g. 在实例名称与资源组部分,可使用默认值,或根据需求自定义设置。
h. 在登录管理下,您可以使用现有的 SSH 密钥对,或在首次使用时创建新的密钥对。请参考此指南了解如何创建 SSH 密钥对。
i. 点击 下一步:确认订单”以继续。
j. 核对您的云服务器配置,确认无误后,阅读并同意相关协议,然后点击 提交订单。
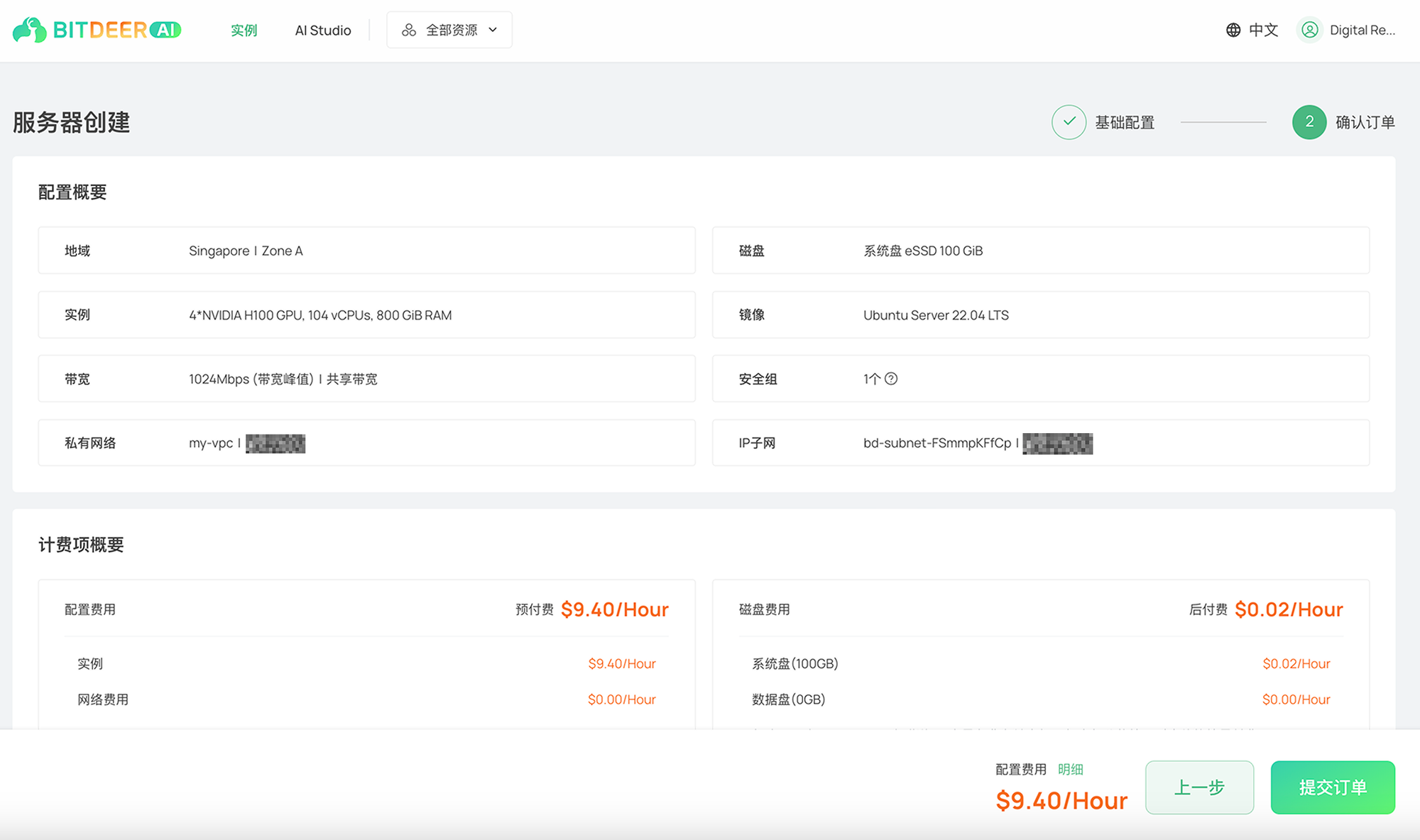
k. 确认付款后,您的云服务器将很快准备就绪。
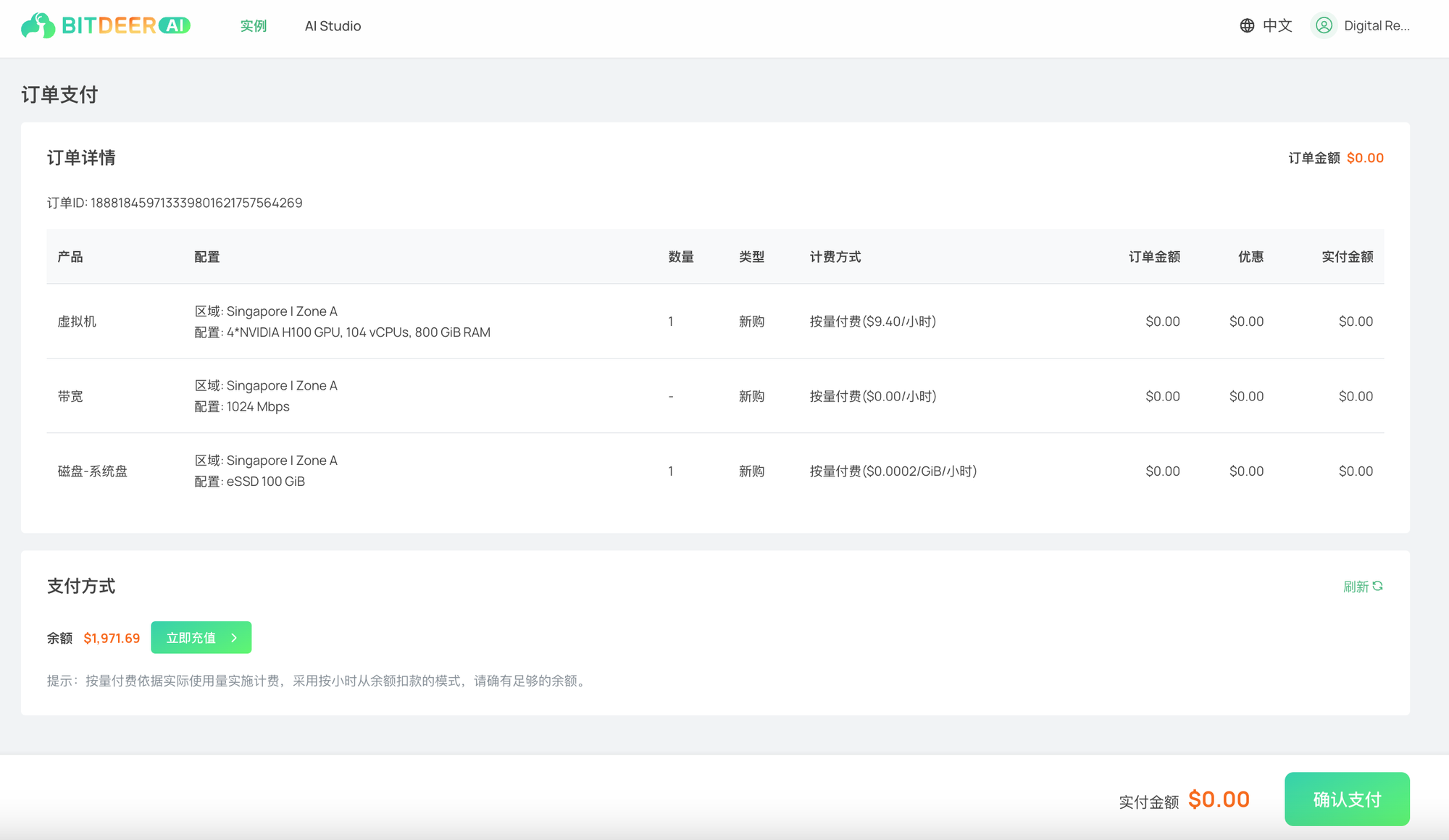
4. 自动部署:
- 完成配置后,系统将自动部署模型并启动服务器。
- 由于模型体积较大,实例初始化大约需要 30 分钟以上。服务器启动后,您将收到通知邮件。
- 请确保服务器状态显示为 Running(运行中)后再使用。
5. 服务器启动后,将自动下载 DeepSeek 模型,建议等待至少 20 分钟以确保加载完成
6. 您可以在云服务器详情页 查看 公网 IP 地址。
在云服务器上使用 DeepSeek
- 你可以通过以下方式使用 DeepSeek-R1:
a. 在网页界面上,直接访问 http://<Public-IP>:40000 与 DeepSeek-R1 进行对话。
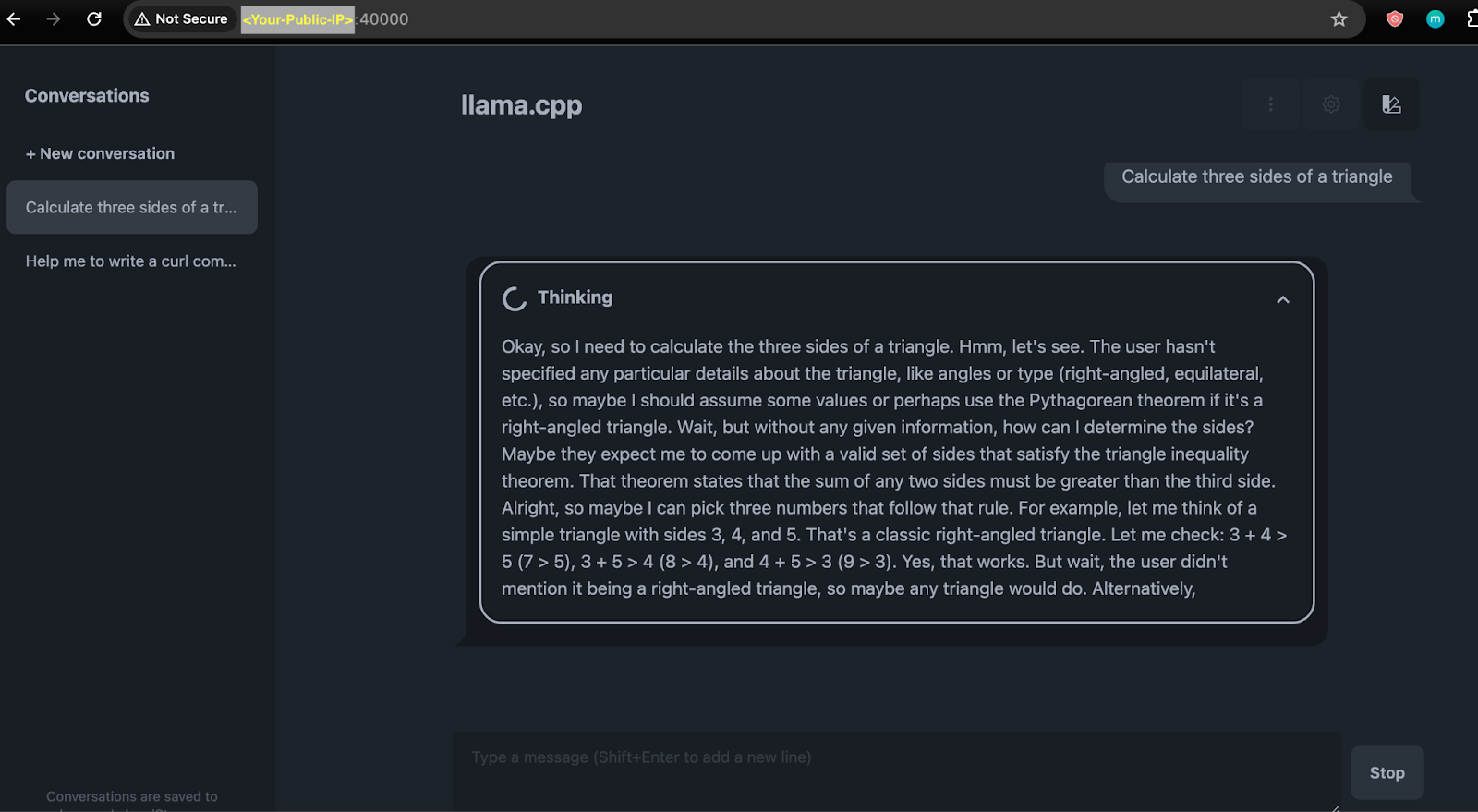
b. 通过 API 调用:由于该 API 遵循 OpenAI 的 RESTful API 标准,你可以通过 http://<Public-IP>:40000/api/chat/completions 或其他相关端点开始调用推理 API。
故障排除
- 问:我尝试使用正确的端口配置 curl 我的公共 IP 地址。 但是,我看到以下消息:The model is loading. Please wait.The user interface will appear soon.答: 在这种情况下,您可以使用以下方法监控模型加载过程。
- SSH 进入您的服务器(确保您的安全组允许使用 TCP 协议通过端口 22 访问 SSH)
- 您可以使用 root 账户,使用 sudo su 命令。 之后,运行 systemctl status llama-server 查看服务器是否正在运行。 它应该显示 Active: active (running)
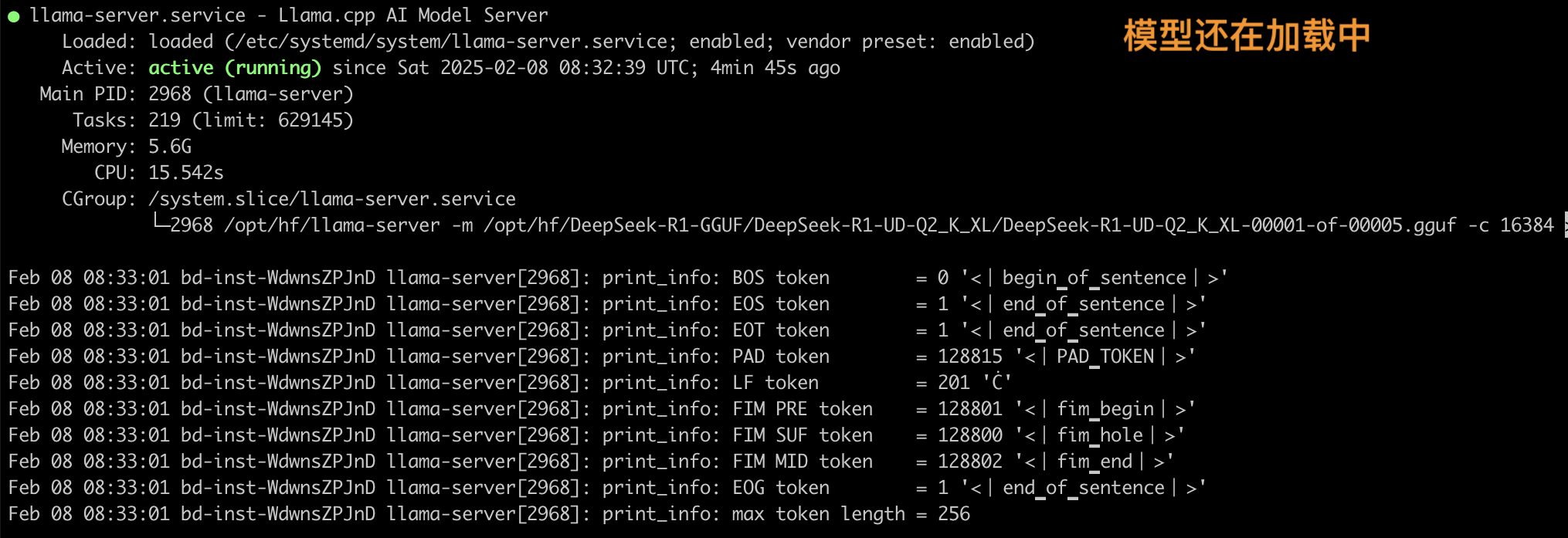
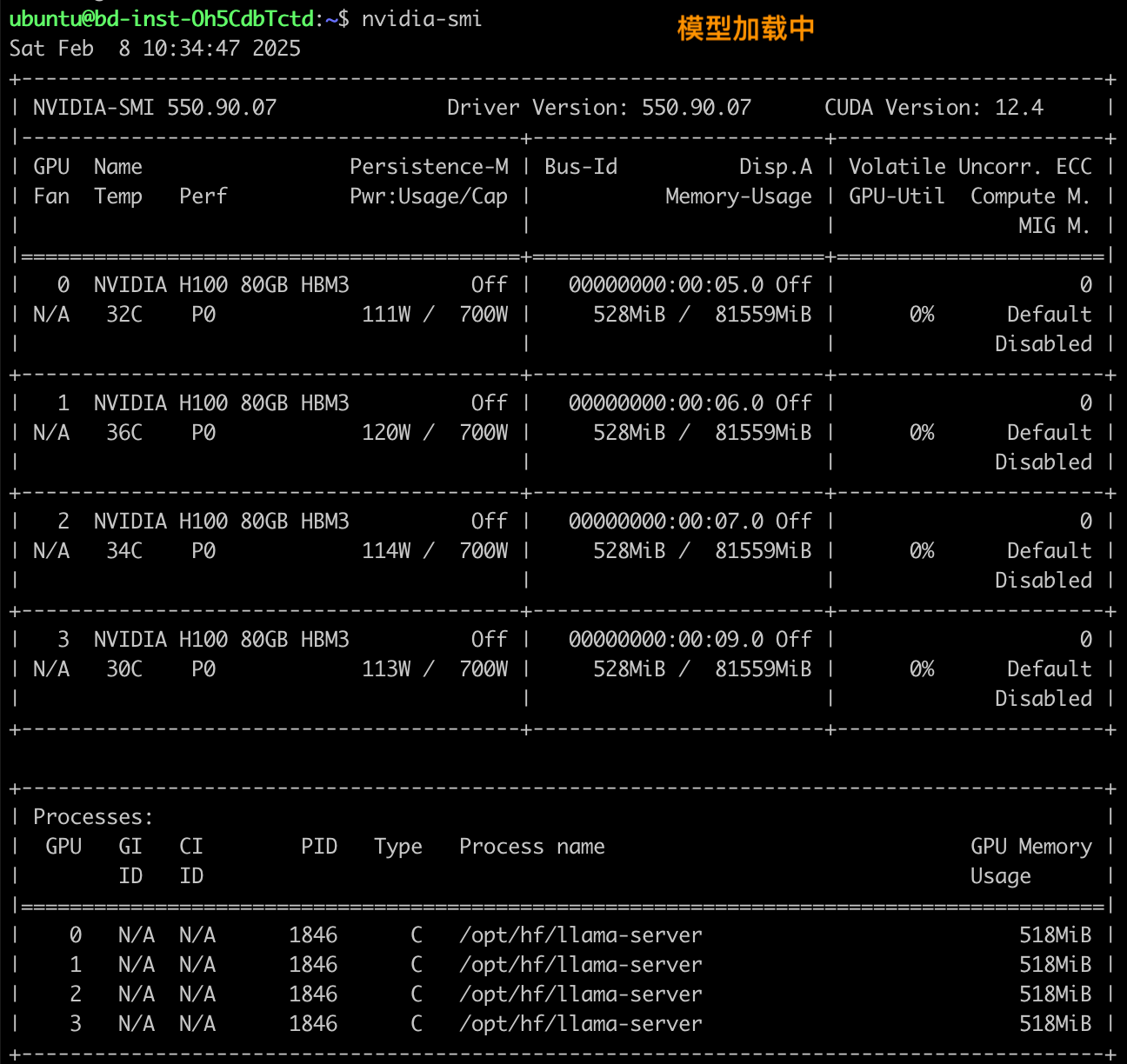
3. 运行 nvidia-smi 查看每个 H100 GPU 的 VRAM 是否被占用。 模型完全加载后,VRAM 总共应占用约 300GB。
为什么选择 Bitdeer AI 虚拟机?
Bitdeer AI 的虚拟机服务为 AI 工作负载提供多种优势,包括:
- 高性能计算: 访问 NVIDIA H100、H200 和其他高端 GPU,用于 AI 训练和推理。
- 可扩展性: 根据工作负载需求轻松扩展资源。
- 优化的网络: 低延迟、高带宽互连,可加快数据传输速度并缩短训练时间。
- 灵活的部署选项: 在裸机服务器(用于专用性能)或虚拟机(用于经济高效的按需 AI 处理)之间进行选择。
- 安全可靠的基础设施: 企业级安全性和 24/7 支持,以确保无缝运营。
在 Bitdeer AI 的虚拟机基础设施上部署 DeepSeek-R1 可以为 AI 模型训练和推理提供强大、可扩展且经济高效的解决方案。 通过遵循本指南,您可以高效地设置和运行 DeepSeek-R1,从而为您的 AI 项目利用 Bitdeer AI 的高性能计算资源。