实现Agentic AI 的关键技术要素
代理型 AI (agentic AI) 代表着自主系统的下一步演进,它超越了传统的响应式语言模型,能够以最少的人类监督执行复杂的多步骤任务。 在实际应用中,构建此类系统需要深度融合先进的模型训练策略和稳健的数据工程。
今天,我们将探讨实现代理型 AI 所需的核心技术组件,重点关注如何训练支持迭代式、链式思维推理的模型,以及如何设计能够实现快速、上下文丰富数据检索的数据库架构。

高级模型训练策略
- 微调与领域特定适配
- 基于领域特定数据的迁移学习:迁移学习通过使用领域特定数据更新预训练模型的特定层,从而在保留模型基础知识的同时,使其更好地适应目标领域。

- 适用于希望模型适应新领域(如法律、医疗或技术文本)而无需引入全新架构的任务。
- 优势: 在保留通用知识的同时,实现针对特定领域的优化适配。
- 自主性强化学习 (RL):
- 层次化强化学习 (HRL):将复杂任务拆解为子目标,以便进行长期规划,例如机器人通过掌握像拾取零件这样的较小动作来完成产品组装。

- 该方法将任务进行层次化结构化,非常适合用于机器人或游戏 AI 中的顺序决策。
- 应用: 非常适合需要长时间持续推理的任务。
- 推理技术:诸如 ReAct、链式思维(CoT)和思维树(Tree-of-Thoughts)等技术被用来引导模型进行逐步推理。这些方法帮助 AI 将复杂任务拆解为逻辑子组件,并结合反馈循环,迭代地优化其策略。
- ReAct(推理 + 行动):将推理与行动(如 API 调用)结合,用于动态环境中。
- 链式思维(CoT):引导模型逐步解决问题,提高复杂场景下的准确性。
- 思维树(ToT):探索多条推理路径,以找到最佳解决方案。

- 这模拟了一个结构化的推理过程,可以适应任何编程环境。
- 使用场景:CoT 在数学或逻辑问题中表现出色,而 ReAct 适用于交互式任务。
- 多模态集成:为了实现全面的情境感知,现代训练策略将多模态数据(如文本、图像和传感器数据)结合起来,使智能体能够更好地感知和推理其环境。当智能体需要同时与数字和物理数据源互动时,这种集成尤为关键。
模型优化的最佳实践
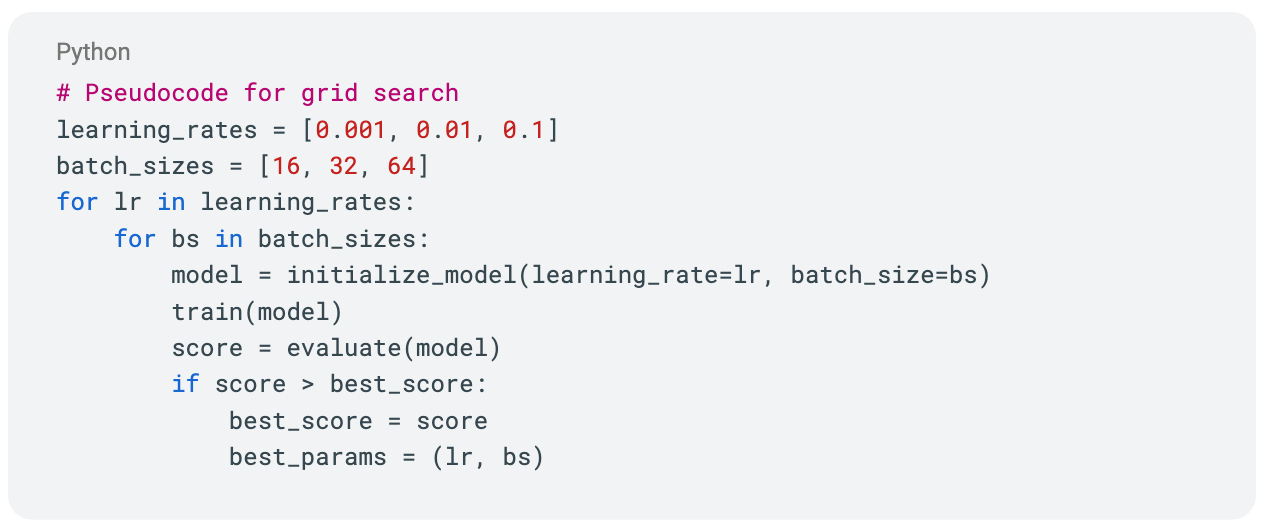
- 超参数调优与迁移学习:利用网格搜索、贝叶斯优化或自动化机器学习(AutoML)等技术,确保模型的学习率、批次大小和其他超参数针对特定任务进行优化。
网格搜索的一个例子:测试学习率和批次大小等参数的组合,以优化性能。
- 正则化与鲁棒性措施:诸如 dropout、权重衰减和数据增强等技术有助于减轻过拟合,确保模型能够很好地泛化到新的、未见过的任务。
- 迭代评估与反馈:通过自动化指标和人工评估相结合的方式进行持续评估,使系统能够动态适应。这个迭代反馈循环对于在不断变化的真实环境中保持高性能至关重要。
代理型 AI 的鲁棒数据库设置
实时决策的数据工程
数据是代理型 AI 系统的核心。设计底层数据基础设施需要考虑以下内容:
- 多源数据集成:代理型 AI 必须能够访问结构化和非结构化数据源。这包括传统的 SQL/NoSQL 数据库、实时数据流,甚至是遗留系统。数据摄取管道应设计为高吞吐量和低延迟。
ETL 管道示例: 为多种数据类型创建提取、转换和加载(ETL)过程。

- 向量数据库与知识图谱:为了有效地实现检索增强生成(RAG)技术,向量数据库存储从文本或多模态数据中生成的嵌入。知识图谱通过提供实体之间的语义关系来补充这一点,增强模型推理上下文和关系的能力。
向量存储示例: 使用嵌入进行快速相似性搜索。

知识图谱示例: 通过构建实体关系图谱来增强推理能力。

- 可扩展、分布式存储:采用基于云的存储解决方案和分布式数据库,确保数据能够随着组织需求的增长而扩展。像 Apache Kafka 这样的流数据技术或云原生数据库(如 Bitdeer AI RDS)提供了必要的基础设施,以支持实时代理型工作流。
- 数据预处理与标准化:稳健的 ETL(提取、转换、加载)过程对于清洗、标准化和规范化数据至关重要。高质量和及时的数据对于模型的性能至关重要,尤其是在需要快速决策的情境下。
实时数据检索与更新
- 低延迟查询机制:为了支持实时决策,数据库必须提供快速的查询响应。索引策略(如在向量相似性搜索中使用的策略)对于快速检索相关上下文至关重要。
- 记忆系统与缓存:在代理型 AI 中,持久化内存架构或内存数据库可以缓存频繁访问的数据。这确保了智能体能够在长期任务中高效地回忆历史上下文并更新其内部状态。
缓存示例: 将频繁使用的数据保存在内存中。

- 安全性与合规性:由于代理型 AI 系统通常访问敏感的企业数据,因此加密、访问控制和审计日志至关重要。数据治理框架必须确保遵守监管标准,如 GDPR 或 HIPAA,尤其是在智能体操作于医疗或金融等领域时。
将模型训练与数据库架构集成
实现代理型 AI 的真正自主性依赖于先进的模型训练与稳健的数据基础设施的无缝集成。一些集成技术包括:
- 模型与数据之间的反馈循环:模型不断查询数据库以获取上下文信息,然后用新的洞察或学习到的参数更新数据库。这种双向的信息流动使得智能体能够保持情境感知,并随着时间推移不断改进。
示例: 智能体用新的洞察更新数据库,触发信息保持。

- 链式思维推理中的动态数据检索:当智能体采用链式思维推理时,它可以动态地查询向量数据库或知识图谱,以检索最相关的上下文。这使得智能体能够根据最新数据调整其推理过程,确保决策保持最新。
方法示例: 在每个推理步骤中查询数据库以获取最新的上下文。

- 模块化系统架构:通过解耦模型训练和数据管理层,工程师可以独立更新这两个组件。这种模块化设计对于保持系统的敏捷性至关重要,尤其是在新数据源可用或模型进一步优化时。
挑战与未来发展方向
尽管已有诸多进展,模型训练和数据库系统的协调仍面临挑战:
- 可扩展性与延迟的权衡:平衡分布式数据库的可扩展性与低延迟响应的需求是一个持续的技术挑战。
- 持续的数据质量保证:确保输入数据始终保持高质量对于维持模型性能至关重要,尤其是在处理实时数据流时。
- 安全性与伦理考量:将先进的 AI 与敏感数据集成需要严格的安全协议和伦理框架,以防止滥用并保护用户隐私。
展望未来,神经形态计算和自适应、自修复数据库的创新可能进一步增强模型训练与数据管理在代理型 AI 系统中的协同作用。构建能够自主规划、推理和行动的代理型 AI 系统,要求将先进的模型训练技术与稳健、实时的数据库架构无缝集成。