什么是 AI 中的 Token?开发人员和企业的全面指南

人工智能(AI)的日益普及使越来越多的人开始了解它,而大语言模型(LLM)是其中最为人熟知的部分之一。在大语言模型(如 DeepSeek 或 ChatGPT)中,核心存在一个称为“Token”的概念。然而,您可能尚未深入了解 Token 的具体含义及其重要性。在本文中,我们将带您深入探索 Token 的世界,包括:Token 的概念、技术定义、不同模型中的 Token 化过程、定价考量、Token 限制,以及 AI 开发者应注意的商业影响。
理解 Token:AI 语言的基本构建单元
什么是 Token?
Token 是 AI 模型处理文本的离散单元,用于理解和生成类人语言。根据分词方法的不同,一个 Token 可以表示一个完整的单词(例如“intelligence”)、一个子词(例如“intelli”),甚至是一个单一字符(例如“i”)。通过将文本分解为 Token,AI 系统能够系统地分析和合成语言。Token 不仅仅是一个技术细节——它们是原始文本与机器理解之间的桥梁,支撑着从聊天机器人到代码生成的一切功能。
Token 的大小根据情境而存在差异:
- 英文文本:平均而言,1 个 Token 约等于 0.75 个单词,这是由于子词分词方法的存在(例如,一段 100 词的段落可能包含 130-150 个 Token)。
- 代码或结构化数据:Token 通常表示更小、更密集的单元,从而降低了词与 Token 的比例。
- 复杂脚本(例如中文、日文):单个字符可能构成一个 Token,反映了语言差异。
这种可变性突显了理解 Token 对于优化 AI 性能和成本的重要性。
Token 化的工作原理:从文本到 Token
Token 化是将文本拆分为 Token 以供 AI 处理的过程。这是一个关键步骤,直接影响响应准确性、计算效率和成本。不同的模型采用不同的 Token 化策略,每种策略都适用于特定的使用场景:
- 基于空格的 Token 化:根据空格和标点符号拆分文本。示例:
- 句子:"Artificial Intelligence is evolving rapidly."
- Token:["Artificial", "Intelligence", "is", "evolving", "rapidly", "."](6 个 Token)
- 子词 Token 化(字节对编码,BPE):将单词拆分为子词,以有效处理未知词汇。示例:
- "Artificial" → ["Artifi", "cial"]
- 用于 GPT 模型。
- 基于字符的 Token 化:每个字符作为一个 Token。示例:
- "AI" → ["A", "I"]
- 常用于复杂脚本语言(如中文、日文)。
- WordPiece Token 化:与 BPE 类似,用于 BERT 等模型,通过从词汇表中学习子词单元。由 Google 开发,最初用于日语和韩语的语音搜索。
- SentencePiece Token 化:一种更灵活的方法,能够处理空格、标点符号和罕见词汇。
高效的 Token 化可以减少处理的 Token 数量,从而降低成本并加快响应速度。例如,子词方法在处理词汇表之外的单词时表现出色,而基于字符的方法虽然确保了通用性,但会带来更高的 Token 数量。
Token 限制:约束与考量
每个 AI 模型都有一个 Token 限制——即单次请求中能够处理的 Token 最大数量,包括输入(提示)和输出(响应)。如果超出这一限制,系统会进行截断,丢弃较早的 Token,这可能会导致关键上下文的丢失。
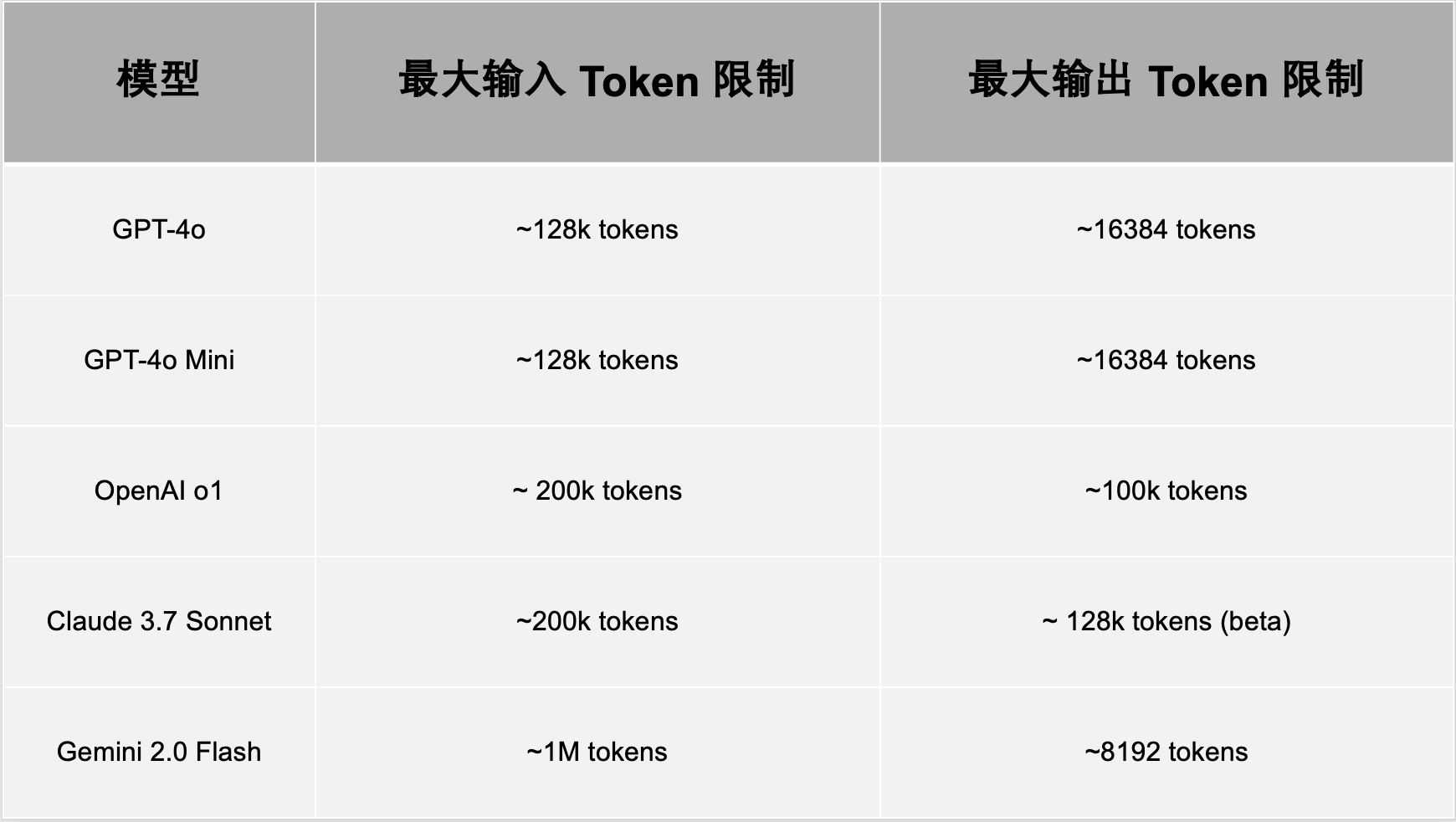
开发者需设计提示(prompt)和响应,以确保其在这些限制范围内,从而保证模型能够保留关键信息。Token 限制会直接影响某些任务的可用性,例如总结长文档或维持长时间的对话。
Token 定价:AI 使用的经济学
像 ChatGPT 和 Gemini 这样的 AI 服务采用基于 Token 的定价模式。公司根据请求中处理的 Token 数量收费。定价通常分为:
- 输入 Token:发送给模型的 Token 数量
- 输出 Token:模型生成的响应 Token 数量
以下是一些目前热门的 LLM 模型的 Token 定价表:
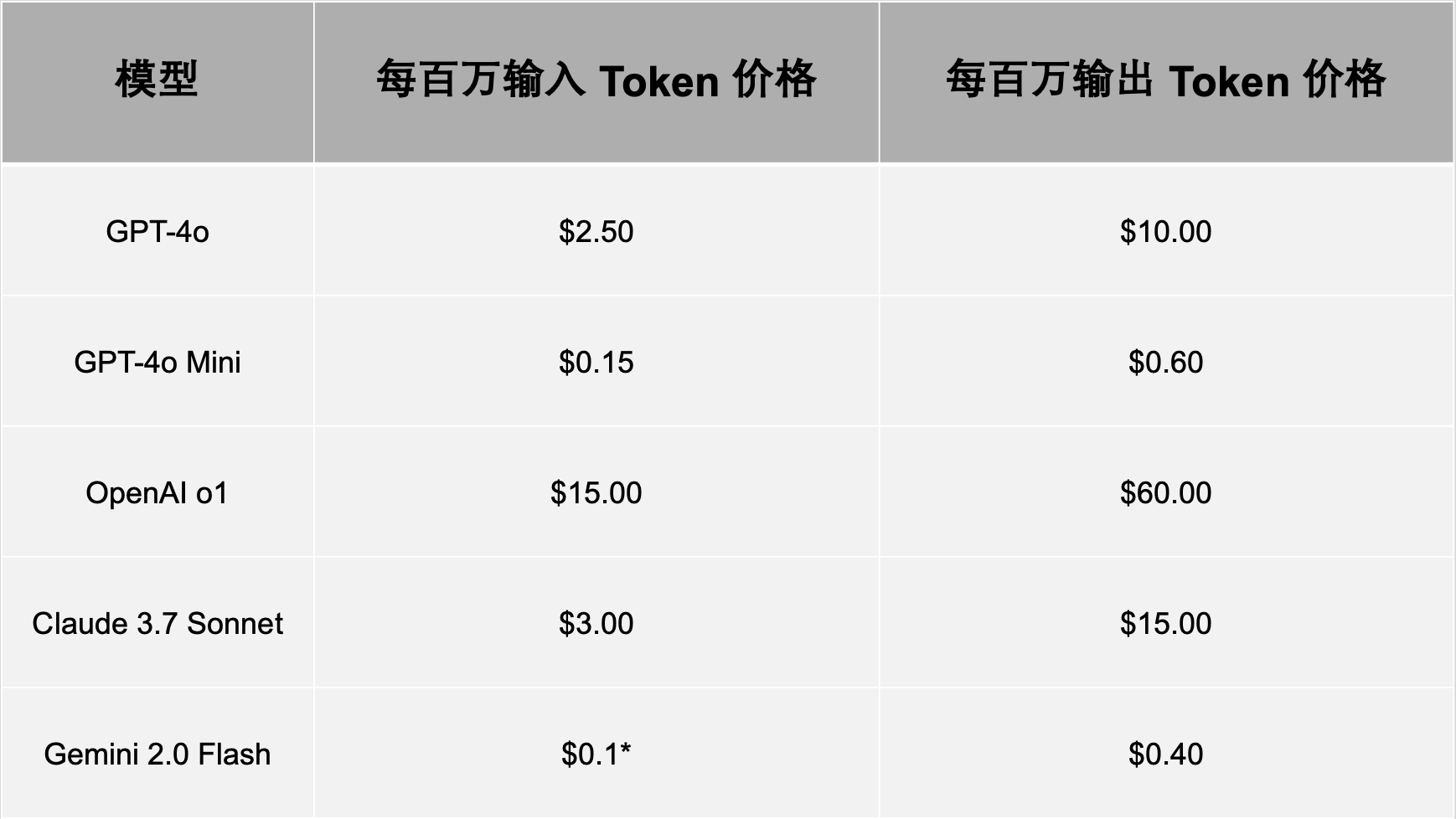
影响 Token 成本的关键因素:
- 模型选择:较大的模型(如 GPT-4o)比较小的模型(如 GPT-4o Mini)更昂贵。
- 输入长度:提示越长,成本越高。精简不必要的词语有助于降低成本。
- 响应长度:限制输出 Token 的数量可以降低费用。
模型训练与性能中的 Token 化
Token 不仅用于推理,还在训练 AI 模型时发挥核心作用。在训练过程中,庞大的数据集被 Token 化,以教导模型语言模式。Token 化方法影响:
- 准确性:糟糕的 Token 化(例如将“AI”拆分为无意义的片段)会使模型困惑。
- 效率:紧凑的 Token 表示降低了计算开销。
- 可扩展性:子词方法使模型能够推广到新单词。
AI 开发者专注于优化 Token 化算法,以提高效率并减少错误。
AI 开发者的商业考量
对于开发者和企业而言,Token 不仅仅影响技术设计——它们还决定了经济性和用户体验:
- 成本管理:在内容生成等应用中,高 Token 使用量可能会侵蚀利润。简洁的提示和高效的模型可以缓解这一问题。
- 性能:超出 Token 限制可能导致关键数据被截断,从而降低输出质量。
- 延迟:处理更多 Token 会减慢响应时间,这对于聊天机器人等实时应用至关重要。
- 商业化:AI 初创公司必须将定价(例如订阅、按使用付费)与 Token 消耗对齐,以确保盈利能力。
优化 Token 使用
为了最大化效率并最小化成本,可以考虑以下技术:
- 提示工程:使用清晰简洁的输入(例如,“总结这个”而不是“请提供这段文本的摘要”)。
- 摘要生成:在输入模型之前对长文本进行预处理以减少 Token 数量。
- 模型选择:根据任务需求选择模型——对于简单查询,使用较小的模型。
- 输出限制:限制响应长度以控制成本和延迟。
总结
Token 是基于大语言模型(LLM)的 AI 应用的基石。理解 Token 化、定价和限制有助于 AI 开发者构建具有成本效益、高效且可扩展的应用。利用 AI 的企业必须将 Token 成本管理纳入其定价和使用策略中,以确保可持续运营。
通过优化 Token 使用并在模型选择和定价方面做出战略决策,AI 开发者可以在保持高性能和准确性的同时降低成本。
补充:
- *此指 Gemini 2.0 Flash(文本 / 图像 / 视频)
- 以上数据收集于 2025 年 2 月。