技术对比分析:DeepSeek V3 vs. DeepSeek V3 (0324)

2025年3月24日,DeepSeek 推出了更新版DeepSeek V3 (0324),优化了模型的性能、输出风格及运营成本。本文将对比分析这两个版本,重点探讨架构创新,并基于 Token 消耗、响应风格及成本影响 等核心指标进行深入评估。
1. DeepSeek V3 (0324) 的核心增强点
1.1 基准性能提升
与原版 V3 相比,DeepSeek V3 (0324) 在多个关键基准测试中表现出显著提升,表明其问题解决能力得到了增强:
- 数学与逻辑推理:
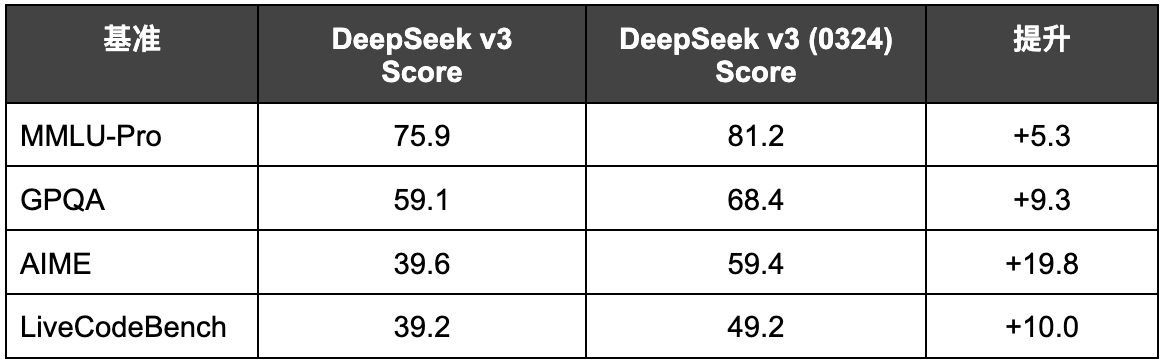
1.2 增强的代码生成与网页开发
- 编码与前端任务: DeepSeek V3 (0324) 生成更清晰、可生产的代码,更好地处理动态 UI 挑战和复杂编程任务。这使其对从事前端网页开发的开发者非常具有吸引力。
1.3 升级的语言与写作能力
- 中文写作能力: 更新后的模型在生成中到长篇中文文本时,提供了更加精细、一致的风格,并且在多轮交互重写和翻译质量上有所提升。这些改进使其更适用于多语言应用。
1.4 函数调用与输出格式化
- 准确的函数调用: DeepSeek V3 (0324) 提高了函数调用的准确性,这是将 AI 输出集成到更广泛软件系统中的关键功能。此举减少了以往在处理结构化输出时的不一致性。
2. 直接对比:Token 使用、响应风格与成本影响
尽管这两个版本共享相同的底层架构,但它们在输出特征和操作成本上有所不同。以下是详细的直接对比:
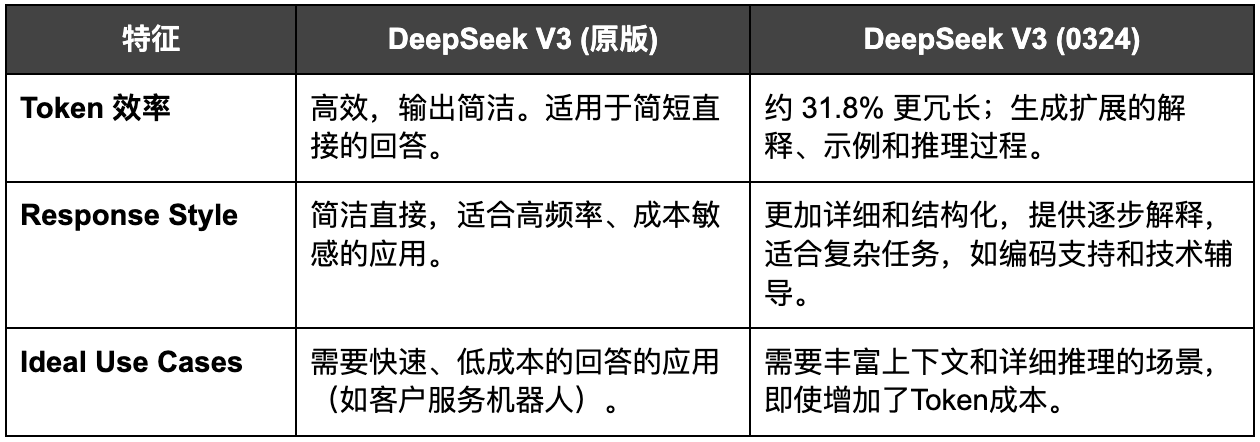
2.1 Token 使用与响应风格
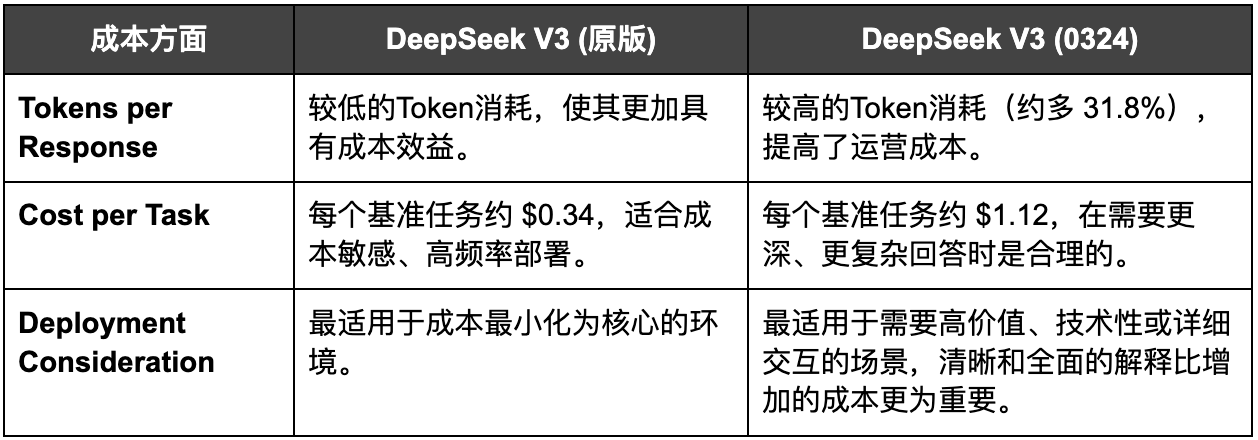
2.2 成本影响
3. 总体影响与部署考虑
- 应用选择:
- DeepSeek V3 (原版): 适用于通用应用,尤其注重速度、Token 效率和成本效益的场景。
- DeepSeek V3 (0324): 更适用于需要详细、清晰和上下文丰富的回答的任务,如高级编码支持、技术辅导和深入推理。
- 操作权衡: 虽然更新版模型的冗长性导致每次交互的成本增加,但这些额外的Token提供了有价值的上下文和逐步推理,能够提高复杂场景下的用户满意度和任务准确性。
- 未来前景: DeepSeek V3 (0324) 的增强不仅提高了开源大语言模型的标准,也可能成为下一代推理模型(如预期中的 R2)的基础。这一发展表明,战略性的技术创新——如强化学习的改进和多Token预测——即使在硬件资源有限的情况下,也能带来显著的性能提升。
以下为两者的快速比较视频:
0:00
/1:00
结论
无论是 DeepSeek V3 还是其更新版 DeepSeek V3 (0324),都在相同高效的 MoE 架构基础上提供了出色的性能。然而,2025年3月的更新在推理基准、代码生成质量、语言输出和函数调用准确性等方面带来了显著改进。
- Token 使用与响应风格: V3 提供简洁的答案,适合快速、成本效益高的应用,而 V3–0324 提供更丰富、详细的回答,适合复杂任务。
- 成本影响: 尽管 V3 (0324) 的冗长性增加了每个任务的成本(从 ~$0.34 增加到 ~$1.12),但这在高价值场景中是可以接受的权衡。
最终,选择哪个版本取决于部署环境的具体需求。对于高频、预算敏感的应用,原版 DeepSeek V3 是非常有效的。而对于需要详细、逐步解释和高级推理的应用,DeepSeek V3 (0324) 是更优的选择。随着 DeepSeek 持续改进其技术,这两个版本都展示了前沿 AI 如何在保持成本效益的同时提供卓越性能,挑战传统范式,并可能重新塑造全球 AI 领域。